一、什么是afl-fuzz
American fuzzy lop 号称是当前最高级的Fuzzing 测试工具之一,由谷歌的Michal Zalewski 所开发。通过对源码进行重新编译时进行插桩(简称编译时插桩)的方式自动产生测试用例来探索二进制程序内部新的执行路径。与其他基于插桩技术的fuzzers 相比,afl-fuzz 具有较低的性能消耗,有各种高效的fuzzing 策略和tricks 最小化技巧,不需要先行复杂的配置,能无缝处理复杂的现实中的程序。当然AFL 也支持直接对没有源码的二进制程序进行测试,但需要QEMU 的支持,将在本文后面做详细介绍。
核心原理:它通过记录输入样本的代码覆盖率,从而调整输入样本以提高覆盖率,增加发现漏洞的概率
二、AFL简介
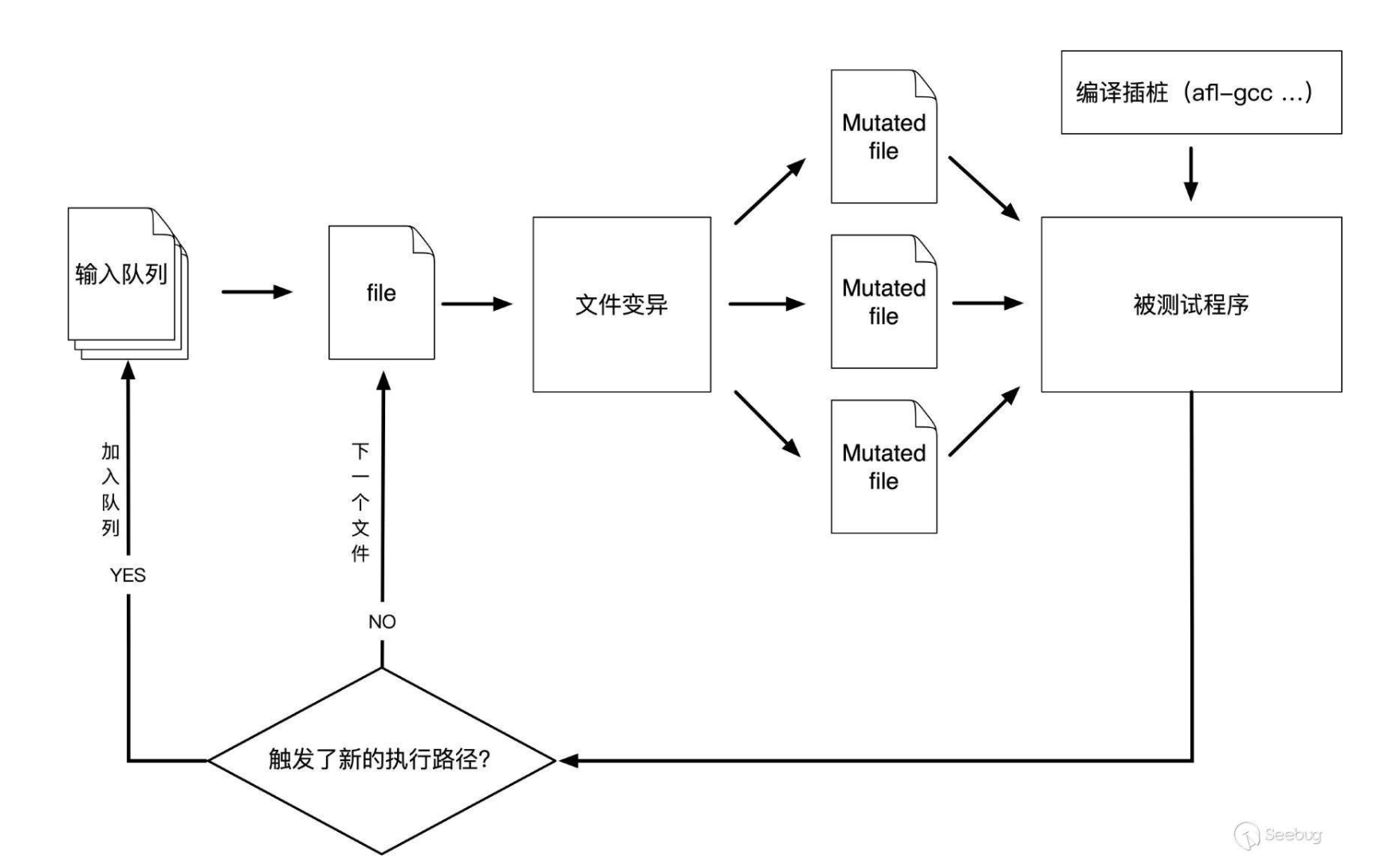
AFL(American Fuzzy Lop)是由安全研究员Micha? Zalewski(@lcamtuf)开发的一款基于覆盖引导(Coverage-guided)的模糊测试工具,它通过记录输入样本的代码覆盖率,从而调整输入样本以提高覆盖率,增加发现漏洞的概率。
①从源码编译程序时进行插桩,以记录代码覆盖率(Code Coverage);
②选择一些输入文件,作为初始测试集加入输入队列(queue);
③将队列中的文件按一定的策略进行“突变”;
④如果经过变异文件更新了覆盖范围,则将其保留添加到队列中;
⑤上述过程会一直循环进行,期间触发了crash的文件会被记录下来。
三、构建语料库
AFL需要一些初始输入数据(也叫种子文件)作为Fuzzing的起点,这些输入甚至可以是毫无意义的数据,AFL可以通过启发式算法自动确定文件格式结构。lcamtuf就在博客中给出了一个有趣的例子——对djpeg进行Fuzzing时,仅用一个字符串”hello”作为输入,最后凭空生成大量jpge图像!
尽管AFL如此强大,但如果要获得更快的Fuzzing速度,那么就有必要生成一个高质量的语料库,这一节就解决如何选择输入文件、从哪里寻找这些文件、如何精简找到的文件三个问题。
1. 选择
(1) 有效的输入
尽管有时候无效输入会产生bug和崩溃,但有效输入可以更快的找到更多执行路径
(2) 尽量小的体积
较小的文件会不仅可以减少测试和处理的时间,也能节约更多的内存,AFL给出的建议是最好小于1 KB,但其实可以根据自己测试的程序权衡,这在AFL文档的perf_tips.txt中有具体说明。
(3)移除执行相同代码的输入文件——AFL-CMIN
afl-cmin的核心思想是:尝试找到与语料库全集具有相同覆盖范围的最小子集。举个例子:假设有多个文件,都覆盖了相同的代码,那么就丢掉多余的文件。其使用方法如下:
1
| afl-cmin -i input_dir -o output_dir -- /path/to/tested/program [params]
|
更多的时候,我们需要从文件中获取输入,这时可以使用“@@”代替被测试程序命令行中输入文件名的位置。Fuzzer会将其替换为实际执行的文件:
1
| $$ afl-cmin -i input_dir -o output_dir -- /path/to/tested/program [params] @@
|
(4) 减小单个输入文件的大小——AFL-TMIN
整体的大小得到了改善,接下来还要对每个文件进行更细化的处理。afl-tmin缩减文件体积的原理这里就不深究了,有机会会在后面文章中解释,这里只给出使用方法(其实也很简单,有兴趣的朋友可以自己搜一搜)。
afl-tmin有两种工作模式,instrumented mode和crash mode。默认的工作方式是instrumented mode,如下所示:
1
| $ afl-tmin -i input_file -o output_file -- /path/to/tested/program [params] @@
|
四、代码覆盖率及其相关概念
代码覆盖率是模糊测试中一个极其重要的概念,使用代码覆盖率可以评估和改进测试过程,执行到的代码越多,找到bug的可能性就越大,毕竟,在覆盖的代码中并不能100%发现bug,在未覆盖的代码中却是100%找不到任何bug的,所以本节中就将详细介绍代码覆盖率的相关概念。
1. 代码覆盖率(Code Coverage)
代码覆盖率是一种度量代码的覆盖程度的方式,也就是指源代码中的某行代码是否已执行;对二进制程序,还可将此概念理解为汇编代码中的某条指令是否已执行。其计量方式很多,但无论是GCC的GCOV还是LLVM的SanitizerCoverage,都提供函数(function)、基本块(basic-block)、边界(edge)三种级别的覆盖率检测,更具体的细节可以参考LLVM的官方文档。
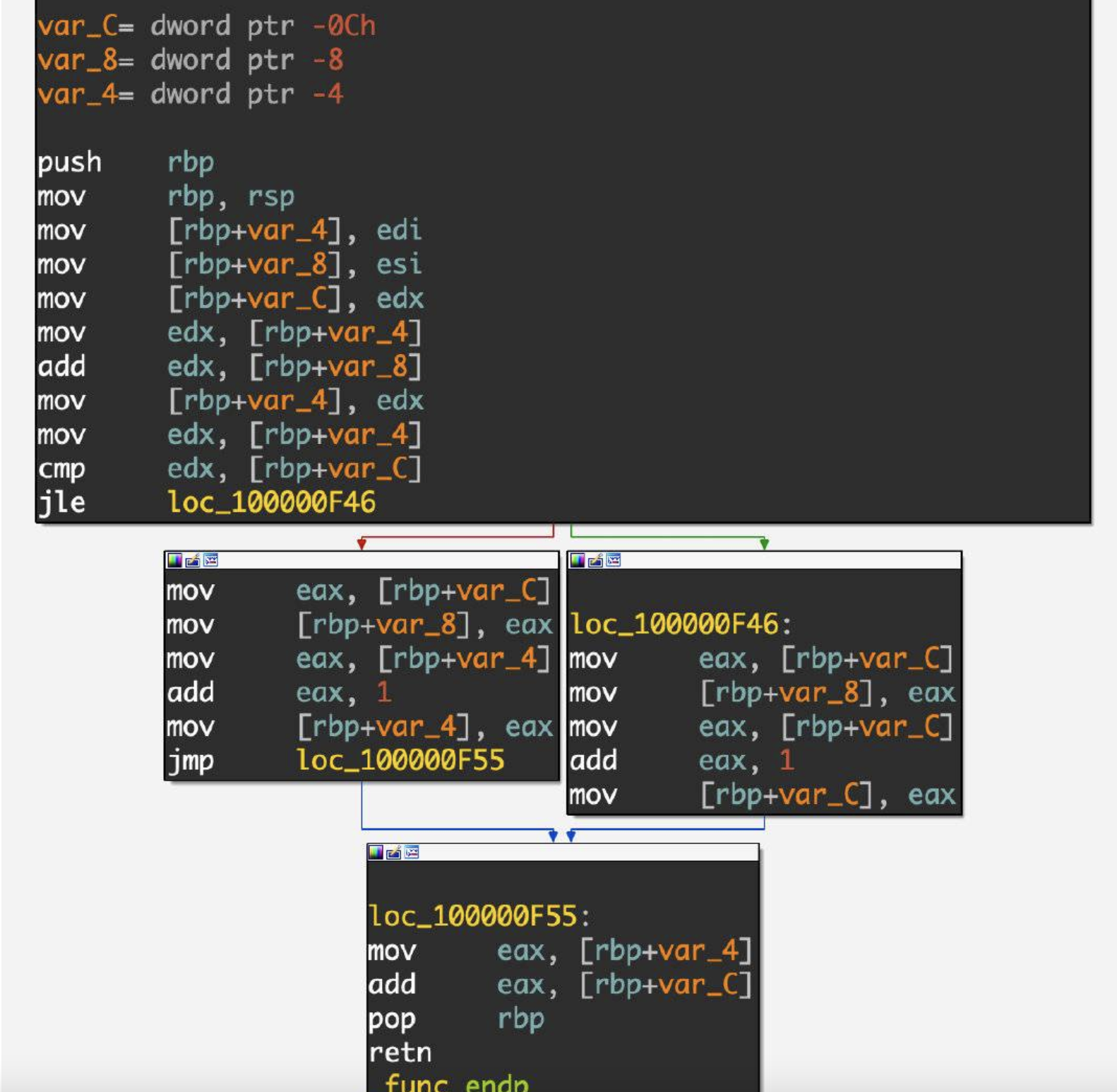
2. 基本块(Basic Block)
缩写为BB,指一组顺序执行的指令,BB中第一条指令被执行后,后续的指令也会被全部执行,每个BB中所有指令的执行次数是相同的,也就是说一个BB必须满足以下特征:
- 只有一个入口点,BB中的指令不是任何跳转指令的目标。
- 只有一个退出点,只有最后一条指令使执行流程转移到另一个BB
3. 边(edge)
AFL的技术白皮书中提到fuzzer通过插桩代码捕获边(edge)覆盖率。那么什么是edge呢?我们可以将程序看成一个控制流图(CFG),图的每个节点表示一个基本块,而edge就被用来表示在基本块之间的转跳。知道了每个基本块和跳转的执行次数,就可以知道程序中的每个语句和分支的执行次数,从而获得比记录BB更细粒度的覆盖率信息。

4. 元组(tuple)
具体到AFL的实现中,使用二元组(branch_src, branch_dst)来记录当前基本块 + 前一基本块 的信息,从而获取目标的执行流程和代码覆盖情况,伪代码如下:
1
2
3
| cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
|
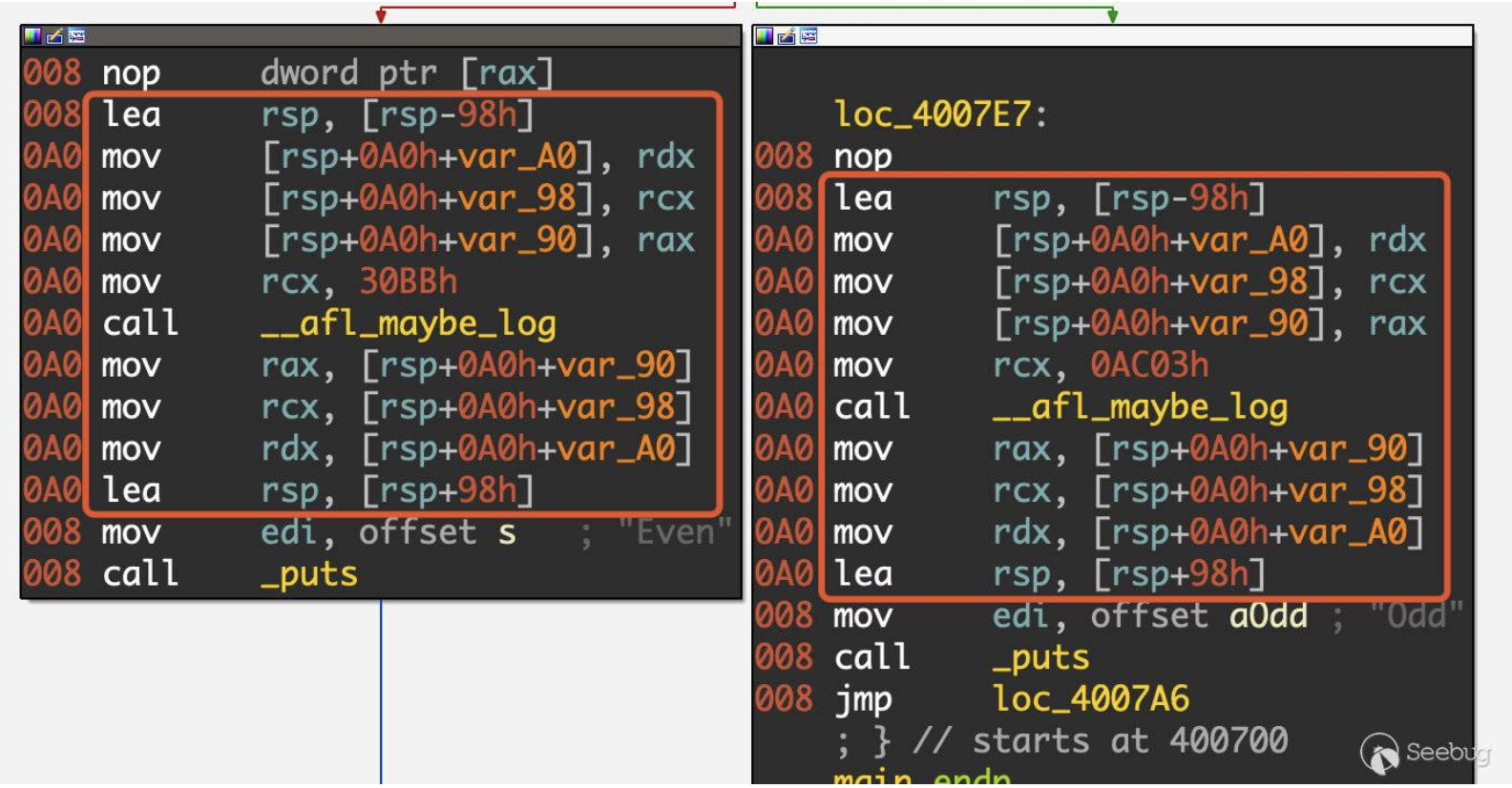
实际插入的汇编代码,如下图所示,首先保存各种寄存器的值并设置ecx/rcx,然后调用__afl_maybe_log,这个方法的内容相当复杂,这里就不展开讲了,但其主要功能就和上面的伪代码相似,用于记录覆盖率,放入一块共享内存中。
5、代码插装的原理分析
我们以afl-gcc为例子分析,通过分析afl-gcc的源码,我们可以知道,这个是个gcc的wrapper,我们通过打印命令行参数可以知道afl-gcc执行的东西:
1
| gcc /tmp/hello.c -B /root/src/afl-2.52b -g -O3 -funroll-loops -D__AFL_COMPILER=1 -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1
|
会发现,本质上还是调用gcc,并设置宏和参数,这里-B设置好了编译器的搜索路径,那么在编译时,就会生成as文件,作为符号链接指向afl-as这个汇编器,执行实际的汇编操作。
对于源码的插桩其实就是通过先将源文件编译成汇编,再通过afl-as来完成的,我们在afl.as中找到关键插入代码的函数:
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE));
先判断是32位还是64位,然后插入相应的代码,这里以32位的为例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| static const u8 *trampoline_fmt_32 =
"\n"
"/* --- AFL TRAMPOLINE (32-BIT) --- */\n"
"\n"
".align 4\n"
"\n"
"leal -16(%%esp), %%esp\n"
"movl %%edi, 0(%%esp)\n"
"movl %%edx, 4(%%esp)\n"
"movl %%ecx, 8(%%esp)\n"
"movl %%eax, 12(%%esp)\n"
"movl $0x%08x, %%ecx\n"
"call __afl_maybe_log\n"
"movl 12(%%esp), %%eax\n"
"movl 8(%%esp), %%ecx\n"
"movl 4(%%esp), %%edx\n"
"movl 0(%%esp), %%edi\n"
"leal 16(%%esp), %%esp\n"
"\n"
"/* --- END --- */\n"
"\n";
static const u8 *trampoline_fmt_64 =
"\n"
"/* --- AFL TRAMPOLINE (64-BIT) --- */\n"
"\n"
".align 4\n"
"\n"
"leaq -(128+24)(%%rsp), %%rsp\n"
"movq %%rdx, 0(%%rsp)\n"
"movq %%rcx, 8(%%rsp)\n"
"movq %%rax, 16(%%rsp)\n"
"movq $0x%08x, %%rcx\n"
"call __afl_maybe_log\n"
"movq 16(%%rsp), %%rax\n"
"movq 8(%%rsp), %%rcx\n"
"movq 0(%%rsp), %%rdx\n"
"leaq (128+24)(%%rsp), %%rsp\n"
"\n"
"/* --- END --- */\n"
"\n";
|
这里我们可以知道是ATT格式的汇编,有%,所以从左往右进行代码阅读,先申请出栈空间用来保存edi等寄存器的值,参数从右往左入栈~这里movq $0x%08x, %%ecx的意思是将第三个参数放入到ecx寄存器中,我们先来看看ecx原本的值是什么,发现是R(MAP_SIZE),这里R(x)=(Random()%x),也就是说R(MAP_SIZE)是从0到64k之间的一个随机数,这里我们可以理解到就是在处理分支时,需要插桩代码时,afl-as先生成一个随机数,作为运行时保存在ecx中的值。而这个随机数,便是用来标识这个代码块的key!关键的代码插装函数就是afl_maybe_log,后面详细分析这个函数。它对于每一个点插入的代码都不一样,代码时随机的,即不考虑碰撞的情况下执行被插入的代码时可以唯一的确定程序当前运行位置。
6、记录执行流
知道怎么获取程序执行的每一个位置,现在要研究存储和利用,我们的目标是用最少的测试用例完成最多的路径覆盖,于是我们需要记住每次执行的路径,若下一次的输入得到了一样的路径就丢弃,有新路径就保存。
1
2
3
| cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
|
下面我们用一张图来说明fuzzer的工作原理
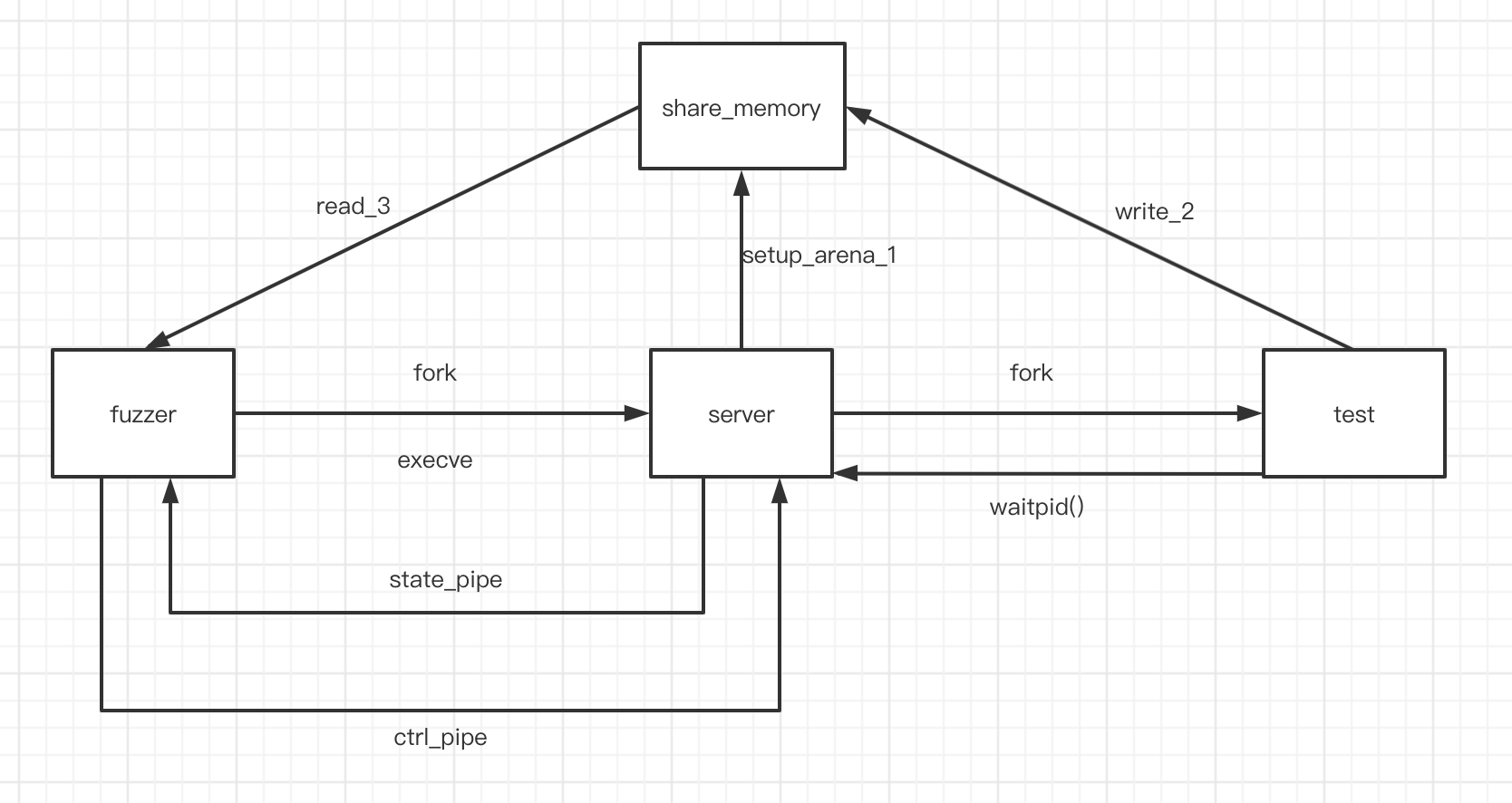
如上图有三种对象:
- fuzzer:即直接执行
afl-fuzz产生的进程。它负责控制fuzzing
- server:由fuzzer使用
fork和execve(target)新建的子进程,它其实是被测程序了,但是它本身不会将测试用例作为输入去执行程序,它将作为一个母体,接受fuzzer的指令,fork出子进程去做真正的测试,并将子进程的pid和其退出状态传递给fuzzer。
- test:由server使用
fork得到的子进程,它将用afl生成的测试用例为输入,执行原有程序逻辑,并将返回的结果报告给父进程(server),再由父进程报告给父进程的父进程(fuzzer)。
通信
如上图三个对象之间需要通信,afl采用了匿名管道,信号和共享内存三种方式:
- 匿名管道:在fuzzer中定义了两个匿名管道:
st_pipe[2], ctl_pipe[2],前者传输状态(数据),方向为server到fuzzer,后者传入指令,方向为fuzzer到server。
- 信号:server在创建子进程后会使用
waitpid等待子进程的信号或事件,得到其改变后的状态后将它传递给fuzzer
- 共享内存:fuzzer要获取test的执行情况,而这些是由test记录的,所以在test结束等事件发生后,fuzzer要获取这些执行流,afl使用共享内存,在fuzzer中申请了一片共享内存用于存储MAP并将其shm_id设置到环境变量中,server会通过环境变量得到shm_id再次打开这片共享内存,之后test就能直接使用它向它里面记录路径,而fuzzer直接可以读test记录的路径了。
7、插装代码执行
现在我们要开始分析__afl_maybe_log函数的定义了,先来看看AFL_VARS:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| "\n"
".AFL_VARS:\n"
"\n"
" .comm __afl_area_ptr, 4, 32\n"
" .comm __afl_setup_failure, 1, 32\n"
#ifndef COVERAGE_ONLY
" .comm __afl_prev_loc, 4, 32\n"
#endif
" .comm __afl_fork_pid, 4, 32\n"
" .comm __afl_temp, 4, 32\n"
"\n"
".AFL_SHM_ENV:\n"
" .asciz \"" SHM_ENV_VAR "\"\n"
|
main_payload_32的定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
| static const u8* main_payload_32 =
".text\n"
".att_syntax\n"
".code32\n"
".align 8\n"
"\n"
"__afl_maybe_log:\n"
"\n"
" lahf\n"
" seto %al\n"
" movl __afl_area_ptr, %edx\n"
" testl %edx, %edx\n"
" je __afl_setup\n"
"\n"
"__afl_store:\n"
"\n"
" /* Calculate and store hit for the code location specified in ecx. There\n"
" is a double-XOR way of doing this without tainting another register,\n"
" and we use it on 64-bit systems; but it's slower for 32-bit ones. */\n"
"\n"
#ifndef COVERAGE_ONLY
" movl __afl_prev_loc, %edi\n"
" xorl %ecx, %edi\n"
" shrl $1, %ecx\n"
" movl %ecx, __afl_prev_loc\n"
#else
" movl %ecx, %edi\n"
#endif
"\n"
#ifdef SKIP_COUNTS
" orb $1, (%edx, %edi, 1)\n"
#else
" incb (%edx, %edi, 1)\n"
#endif
"\n"
"__afl_return:\n"
"\n"
" addb $127, %al\n"
" sahf\n"
" ret\n"
"\n"
".align 8\n"
"\n"
"__afl_setup:\n"
"\n"
" cmpb $0, __afl_setup_failure\n"
" jne __afl_return\n"
"\n"
" pushl %eax\n"
" pushl %ecx\n"
"\n"
" pushl $.AFL_SHM_ENV\n"
" call getenv\n"
" addl $4, %esp\n"
"\n"
" testl %eax, %eax\n"
" je __afl_setup_abort\n"
"\n"
" pushl %eax\n"
" call atoi\n"
" addl $4, %esp\n"
"\n"
" pushl $0 /* shmat flags */\n"
" pushl $0 /* requested addr */\n"
" pushl %eax /* SHM ID */\n"
" call shmat\n"
" addl $12, %esp\n"
"\n"
" cmpl $-1, %eax\n"
" je __afl_setup_abort\n"
"\n"
" /* Store the address of the SHM region. */\n"
"\n"
" movl %eax, __afl_area_ptr\n"
" movl %eax, %edx\n"
"\n"
" popl %ecx\n"
" popl %eax\n"
"\n"
"__afl_forkserver:\n"
"\n"
" pushl %eax\n"
" pushl %ecx\n"
" pushl %edx\n"
"\n"
" /* Phone home and tell the parent that we're OK. (Note that signals with\n"
" no SA_RESTART will mess it up). If this fails, assume that the fd is\n"
" closed because we were execve()d from an instrumented binary, or because\n"
" the parent doesn't want to use the fork server. */\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_temp /* data */\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n"
" call write\n"
" addl $12, %esp\n"
"\n"
" cmpl $4, %eax\n"
" jne __afl_fork_resume\n"
"\n"
"__afl_fork_wait_loop:\n"
"\n"
" /* Wait for parent by reading from the pipe. Abort if read fails. */\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_temp /* data */\n"
" pushl $" STRINGIFY(FORKSRV_FD) " /* file desc */\n"
" call read\n"
" addl $12, %esp\n"
"\n"
" cmpl $4, %eax\n"
" jne __afl_die\n"
"\n"
" /* Once woken up, create a clone of our process. This is an excellent use\n"
" case for syscall(__NR_clone, 0, CLONE_PARENT), but glibc boneheadedly\n"
" caches getpid() results and offers no way to update the value, breaking\n"
" abort(), raise(), and a bunch of other things :-( */\n"
"\n"
" call fork\n"
"\n"
" cmpl $0, %eax\n"
" jl __afl_die\n"
" je __afl_fork_resume\n"
"\n"
" /* In parent process: write PID to pipe, then wait for child. */\n"
"\n"
" movl %eax, __afl_fork_pid\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_fork_pid /* data */\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n"
" call write\n"
" addl $12, %esp\n"
"\n"
" pushl $0 /* no flags */\n"
" pushl $__afl_temp /* status */\n"
" pushl __afl_fork_pid /* PID */\n"
" call waitpid\n"
" addl $12, %esp\n"
"\n"
" cmpl $0, %eax\n"
" jle __afl_die\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_temp /* data */\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n"
" call write\n"
" addl $12, %esp\n"
"\n"
" jmp __afl_fork_wait_loop\n"
"\n"
"__afl_fork_resume:\n"
"\n"
" /* In child process: close fds, resume execution. */\n"
"\n"
" pushl $" STRINGIFY(FORKSRV_FD) "\n"
" call close\n"
"\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) "\n"
" call close\n"
"\n"
" addl $8, %esp\n"
"\n"
" popl %edx\n"
" popl %ecx\n"
" popl %eax\n"
" jmp __afl_store\n"
"\n"
"__afl_die:\n"
"\n"
" xorl %eax, %eax\n"
" call _exit\n"
"\n"
"__afl_setup_abort:\n"
"\n"
" /* Record setup failure so that we don't keep calling\n"
" shmget() / shmat() over and over again. */\n"
"\n"
" incb __afl_setup_failure\n"
" popl %ecx\n"
" popl %eax\n"
" jmp __afl_return\n"
|
从上面可以看出来,在第一次调用afl_maybe_log时,afl_arena_ptr未被设置,就会进入afl_setup处,它设置完会进入afl_fork_server处,之后该进程会一直循环等待fuzzer的指令,收到指令就会fork出子进程test,test再次调用afl_maybe_log时由于alf_arena_ptr已被设置不会再进入这些代码,而会直接进入__afl_store存储路径并返回
我们用一张图再次深刻理解下这个原理和过程
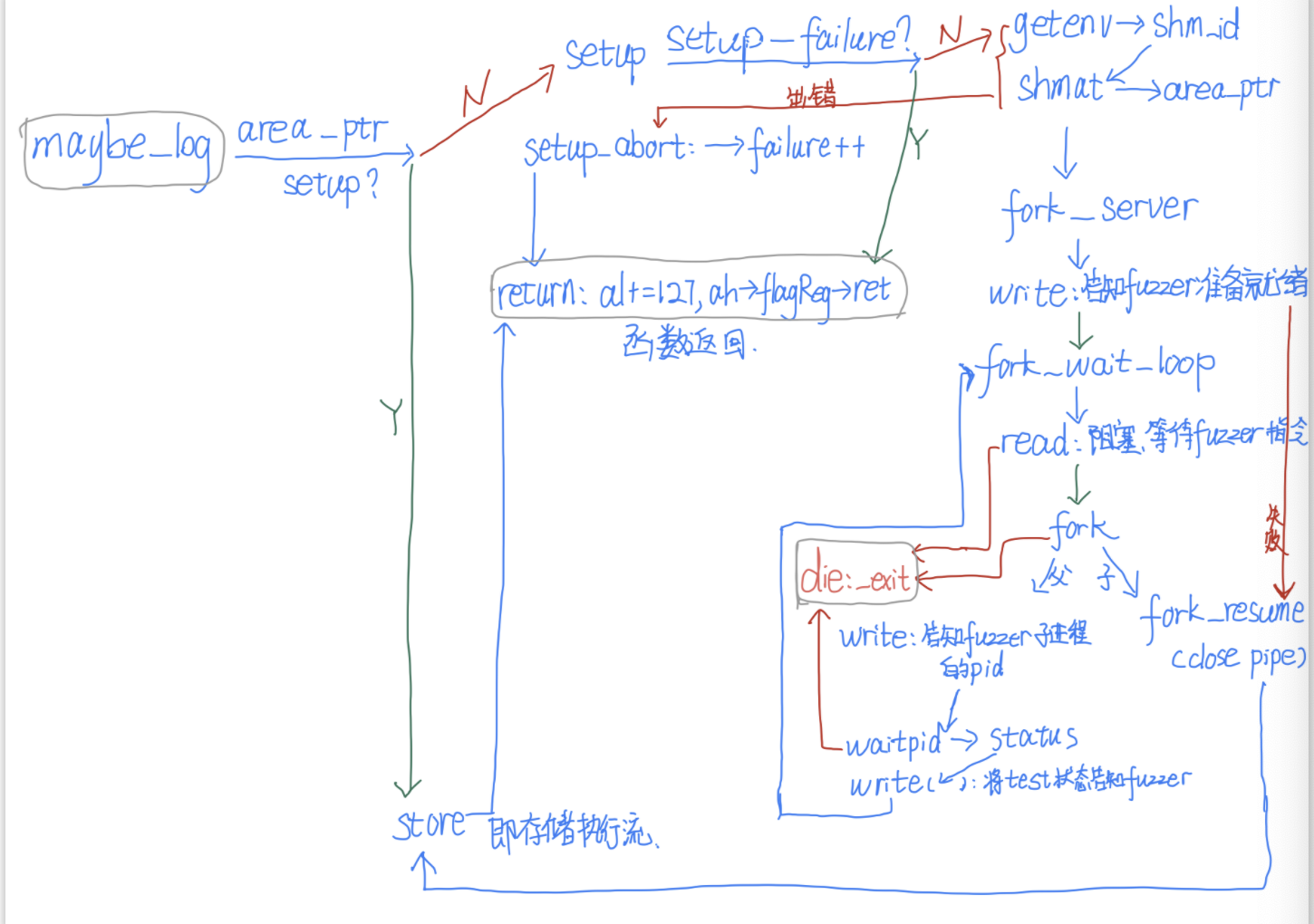
到这里我们已经能够知道测试用例的结果了
8、生成测试用例
afl可以使用自己定义的特值(即词典),作用是可以加快fuzz的速度,毕竟有效的测试用例很重要!
1.user extras (over),从头开始,将用户提供的tokens依次替换到原文件中
2.user extras (insert),从头开始,将用户提供的tokens依次插入到原文件中
3.auto extras (over),从头开始,将自动检测的tokens依次替换到原文件中
注意使用不同种方法可能会生成相同的用例,当遇到已经被测试过的用例将跳过不再重复测试它
effector map
afl能推测一种对于执行流没有影响的数据,对这种数据进行变异将是没有多大意义的,这里把它定义为无效的,他的具体识别方法是若一byte数据完全翻转后都不改变执行流,那么就认为它是无效的,为此afl可以生成一张effector map表表明可能得有效数据的范围,以后变异也只是对有效数据进行变异。一般情况下有3种:
1、使用dumb mode或者从fuzzer
2、文件小于128字节
3、当90%都是有效的那么剩下的就认为是有效的
常见的变异方式:
bitflip
这将按照一定的规律反转比特位
arithmetic
对数据进行算术运算
havoc
进行随机次变异,每次变异随机选择一种变异方式。
splice
选择两个差别较大的用例,随机选择一个位置将它们收尾分割,交叉组合形成新的用例.
五、源码阅读