一、下载与安装 这里附上官网下载地址:https://lcamtuf.coredump.cx/afl/
下载下来解压后,放到虚拟机中,进入文件夹,执行下面的命令进行安装:
说明安装好了,这里解析下每个文件的作用
1 2 3 4 5 6 7 8 9 10 afl-gcc和afl-g++ 分别对应 gcc和g++的封装 afl-clang和afl-clang++ 分别对应clang的c和c++的封装 afl-fuzz 是AFL的主体,用于对目标程序进行fuzz afl-analyze可以对用例进行分析,通过分析给定的用例,看能否发现用例中有单方的字段 afl-qemu-trace 用于qemu-mode,默认不安装 afl-plot 生成测试任务的状态图 afl-tmin 和afl-cmin 对用例进行简化 afl-whatsup 用于查看fuzz任务的状态 afl-gotcpu 用于查看当前 cpu 状态 afl-showmap 用于对单个用例进行执行路径跟踪
二、白盒测试 准备一个测试用例1.c,这样我们可以通过afl对源码重新编译时进行插桩
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <signal.h> int vuln (char *str) int len = strlen (str); if (str[0 ] == 'A' && len == 66 ) { raise(SIGSEGV); } else if (str[0 ] == 'F' && len == 6 ) { raise(SIGSEGV); } else { printf ("it is good!\n" ); } return 0 ; } int main (int argc, char *argv[]) char buf[100 ]={0 }; gets(buf); printf (buf); vuln(buf); return 0 ; }
对于c语言程序的插桩编译命令如下:
1 afl-gcc -g -o afl_demo 1. c
如果是c++程序,就换成afl-g++即可,这里其实想过mips或者arm框架的程序源码插桩,不过可能需要交叉编译。
插好桩后,生成afl_demo程序,这时还需要输入文件和输出文件的存储位置,所以我们创建2个文件,fuzz_in和fuzz_out的文件夹,在fuzz_in里面创建一个输入样例democase,里面输入aaaa
准备工作做好了,正式进行fuzz工作,运行下面的命令
1 afl-fuzz -i fuzz_in -o fuzz_out ./afl_demo
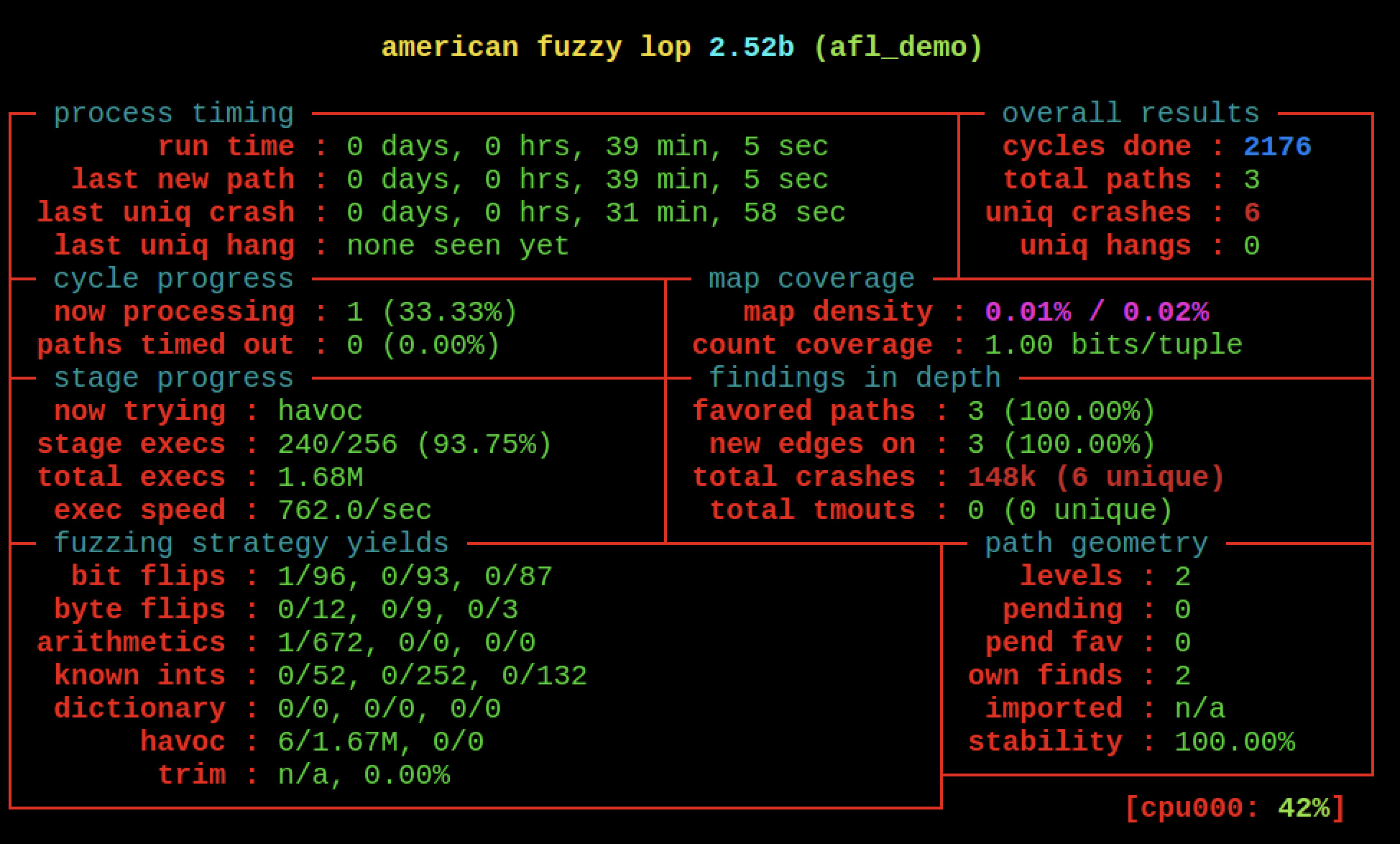
下面是fuzz工作的UI界面
简单讲解下,每个模块的意义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 process timing:run time :当前fuzzer的运行时间last new path :最近一次发现新路径的时间 last uniq crash :最近一次崩溃的时间 last uniq hang :最近一次超时的时间 # 值得注意的是第2 项,最近一次发现新路径的时间。如果由于目标二进制文件或者命令行参数出错,那么其执行路径应该是一直不变的,所以如果从fuzzing开始一直没有发现新的执行路径,那么就要考虑是否有二进制或者命令行参数错误的问题了。对于此状况,AFL也会智能地进行提醒。 overall results: cycles done:总周期数 total paths:总路径数 uniq crashes:崩溃次数 uniq hangs:超时次数 #其中,总周期数可以用来作为何时停止fuzzing的参考。随着不断地fuzzing,周期数会不断增大,其颜色也会由洋红色,逐步变为黄色、蓝色、绿色。一般来说,当其变为绿色时,代表可执行的内容已经很少了,继续fuzzing下去也不会有什么新的发现了。此时,我们便可以通过Ctrl-C,中止当前的fuzzing。 stage progress: now trying :正在测试的fuzzing策略 stage execs :进度 total execs :目标执行总次数 exec speed :目标执行速度 cycle progress now processing :处理进度 paths timed out :路径超时 #周期进度 map coveragemap density: 地图密度count coverage: 计数范围 #框中的第一行告诉您我们已经有多少个分支元组与位图可以容纳的比例成正比。左边的数字描述当前输入;右边的是整个的价值输入语料库。第二行处理的是元组点击计数中的变化 findings in depth favored paths: 首选路径 new edges on: 新边缘total crashes: 总崩溃次数 total tmouts: 总淘汰次数 #模糊器最喜欢的路径数(这些路径将获得更长的播放时间),以及实际上导致更好的边缘覆盖率的测试用例的数量(相对于只是增加分支命中计数器的数量)。还有其他更详细的计数器,用于崩溃和超时。 fuzzing strategy yields bit flips: 翻转byte flips: 字节翻转arithmetics: 算术 known ints: 已知整数 dictionary: 字典 havoc: 破坏 trim: 修剪 #模糊测试的收益 -校准-预模糊阶段,其中检查执行路径 以检测异常,确定基线执行速度等。 只要有新发现,就会非常简短地执行。 -修剪L / S-另一个预模糊阶段,在该阶段中,将测试用例修剪为 最短的形式,仍然产生相同的执行路径。长度(L) 和步长(S)通常根据文件大小来选择。 -bitflip L / S-确定性的位翻转。在任何给定 时间切换L位,使输入文件以S位递增。当前的L / S变体 为:1 / 1 、2 / 1 、4 / 1 、8 / 8 、16 / 8 、32 / 8 。 -arith L / 8 -确定性算术。模糊器试图将 小整数减去或加到8 位,16 位和32 位值。步进总是8 位。 -利息L / 8 -确定性值覆盖。模糊器有一个已知的 “有趣的” 8 位,16 位和32 位值列表供您尝试。步进为8 位。 -额外功能-确定性地注入词典术语。这可以显示为 “用户”或“自动”,这取决于模糊器是使用用户提供的 词典(-x)还是自动创建的词典。您还会看到“ over”或“ insert”, 具体取决于字典单词是覆盖现有数据还是 通过偏移剩余数据以适应其长度来插入。 -破坏-具有一定长度的周期,带有堆叠的随机调整。 在此阶段尝试的操作包括位翻转,使用 随机和“有趣的”整数进行覆盖,块删除,块复制以及 各种与字典相关的操作(如果 首先提供字典)。 -拼接-一种最后的策略,在 没有新路径的第一个完整队列周期后开始执行。它等效于“破坏”,除了它首先 在任意 选择的中点将来自队列的两个随机输入拼接在一起。 -sync-仅当设置-M或-S时使用的阶段(请参见parallel_fuzzing.txt)。 不涉及真正的模糊测试,但是该工具会扫描其他 模糊测试器的输出,并根据需要导入测试用例。第一次执行此操作 可能需要几分钟左右。 path geometry level: 级别 pending: 待定 pend fav:最喜欢的 own finds: 自己的发现 imported: 导入 stability: 稳定性 此部分中的第一个字段跟踪通过 指导的模糊过程达到的路径深度。本质上: 用户提供的初始测试用例被认为是“ 1 级”。 通过传统的模糊测试可以从中得出的测试用例被认为是“ 2 级”。通过 将它们用作后续模糊测试回合的输入而得出的结果为“ 3 级”;等等。 因此,最大深度可以大致代表您 从af-fuzz采取的仪器指导方法中获得的价值。 下一个字段显示 尚未经过任何模糊测试的输入数量。还为模糊测试器的“收藏”条目提供了相同的统计信息 确实想进入这个队列周期(非优先项可能需要 等待几个周期才能获得机会)。 接下来,我们获得了在此模糊测试部分发现的并 在进行并行化模糊测试时从其他模糊测试器实例导入的新路径的数量;以及 相同输入的出现程度有时会 在测试的二进制文件中产生可变的行为。 最后一点实际上很有趣:它可以测量 观察到的迹线的一致性。如果程序对于相同的输入数据始终表现相同, 则它将获得100 %的分数。当该值较低但仍显示为紫色时, 模糊过程不太可能受到负面影响。如果变成红色, 您可能会遇到麻烦,因为AFL难以区分 调整输入文件的有意义和“幻像”效果。 现在,大多数目标只会得到100 %的分数 #几何路径 cpu0000: cpu的负载,绿色表示可观,可能可以并行提高性能
需要注意几点:
1、last new path 如果报错,那么要及时修正命令行参数,不然继续fuzz也是徒劳(因为路径是不会改变的);
2、cycles done 如果变绿了,说明后面即使继续fuzz的意义也不大了,因为出现crash的几率已经很低了,可以选择这个时候停止fuzz
3、uniq crashes 代表的是crash的数量
4、exec speed可以直观地反映当前跑得快不快,如果速度过慢,比如低于500次每秒,那么测试时间就会变得非常漫长,这时候就需要进一步调整优化我们的fuzzing,如果您想立即获得更广泛但更浅的覆盖范围,请尝试
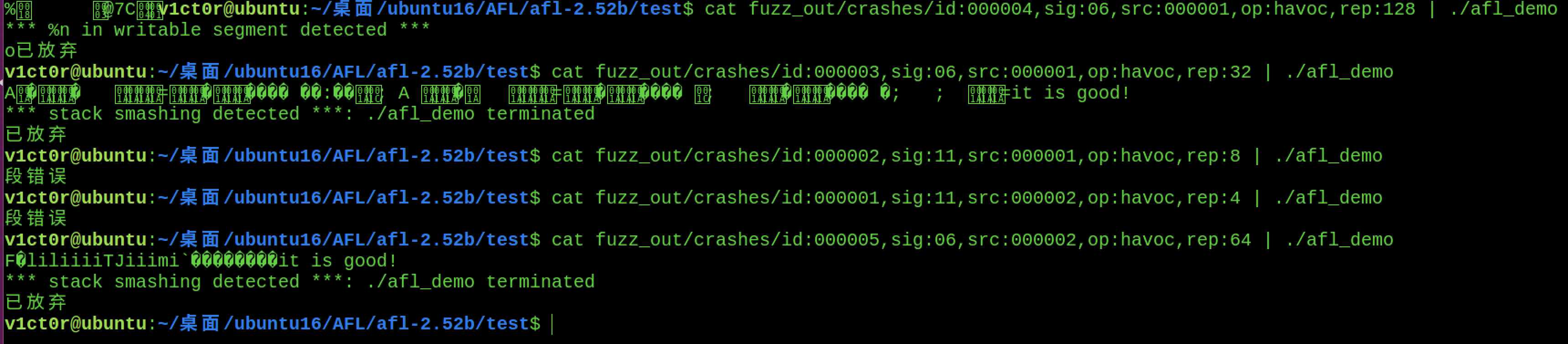
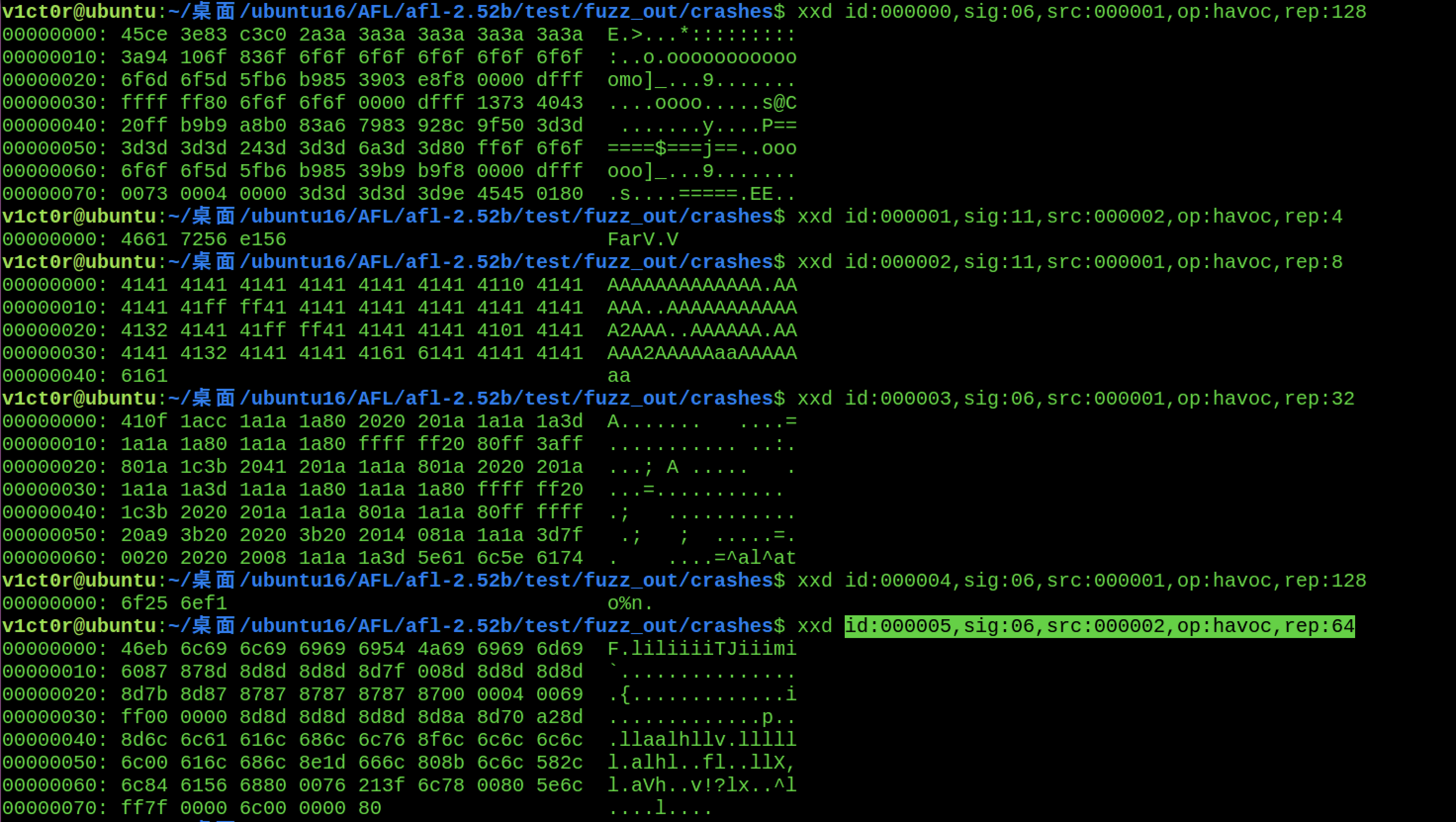
下面看下fuzz过后crashes中的情况:xxd表示以16进制的形式去表示一个数据,例如
1 xxd id:000000 ,sig:06 ,src:000001 ,op:havoc,rep:128
可以用cat命令看看效果是怎么样的~
例如
1 cat fuzz_out/crashes/id:000002 ,sig:11 ,src:000001 ,op:havoc,rep:8 | ./afl_demo
也就是说,这样子可以在程序开发时,自己手动fuzz,检测漏洞
三、黑盒测试 这里安装qemu_mode前,需要装3个东西,按照以下命令执行安装
1 2 3 4 5 6 7 sudo apt-get install libtool sudo apt-get install libtool-bin which libtool #会看到回显示/usr/bin/libtool cd qemu_mode ./build_qemu_support.sh cd .. sudo make install
这里会解压完报错说某个文件已经存在,那么我们直接跳过解压过程,通过修改build_qemu_support.sh文件,这里修改成如下:把这2行直接注释掉
接着继续跑一次:
1 2 3 ./build_qemu_support.sh cd .. sudo make install
装好后如下:
下面进行黑盒测试:自己编译一个文件1.c,同样搞2个文件夹输入输出
1 2 gcc -o afl_hack 1. c afl-fuzz -i fuzz_in -o fuzz_out -Q ./afl_hack #黑盒测试
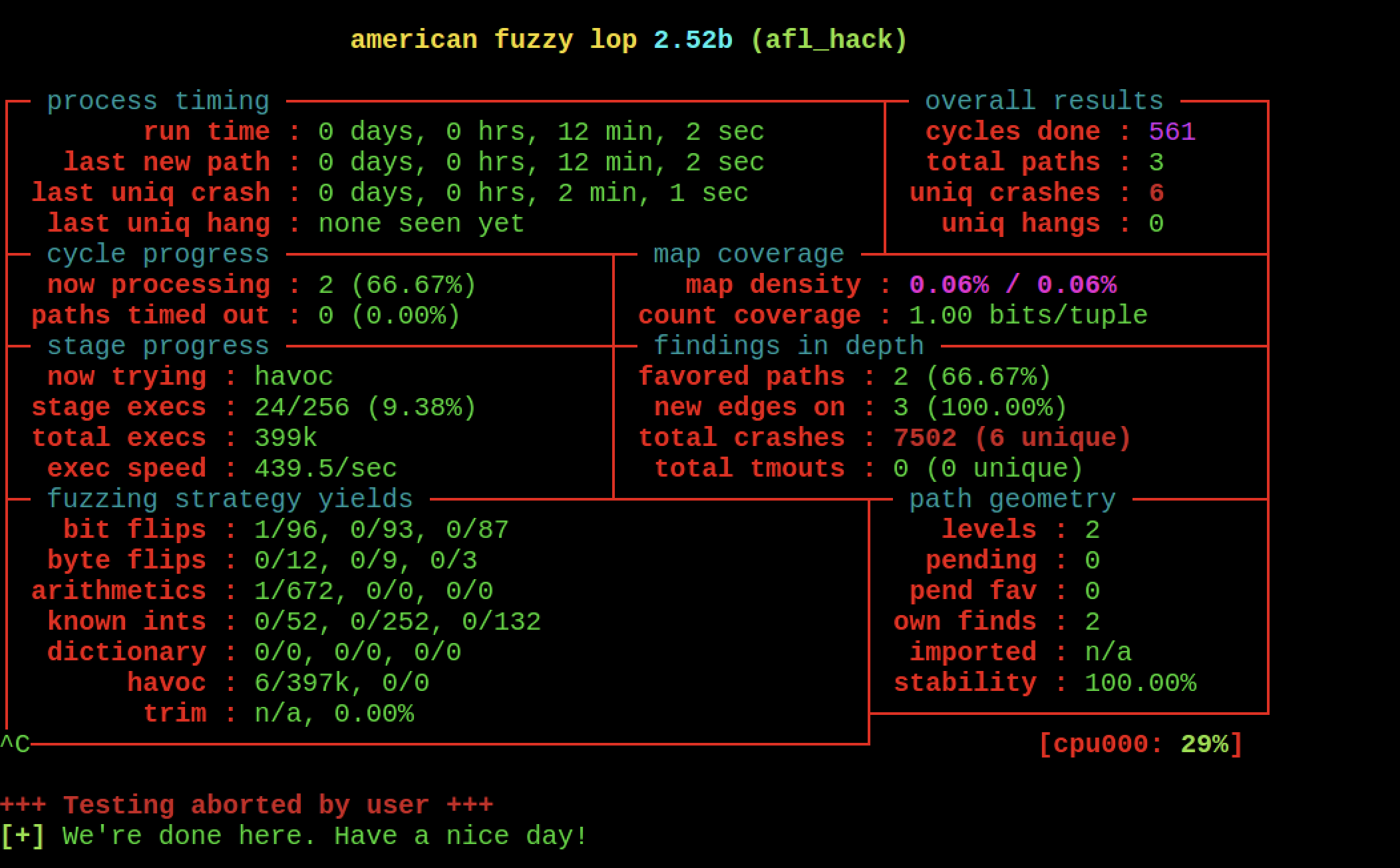
看下crash的情况:
这里6个crash的情况还是不变~
四、并行fuzz了解 如果你有一台多核心的机器 ,可以将一个afl-fuzz绑定到一个对应的核心上,也就是说,机器上有几个核心就可以运行多少afl-fuzz实例,这样可以极大得提高运行速度;
查看机器的核心数cat /proc/cpuinfo | grep "cpu cores" | uniq
afl-fuzz并行fuzzing一般的做法是通过 -M 参数指定一个主Fuzzer(Master Fuzzer)、通过 -S 指定多个从Fuzzer(Slave Fuzzer)
1 2 3 afl-fuzz -i testcases/ -o sync_dir/ -M fuzzer1 -- ./program afl-fuzz -i testcases/ -o sync_dir/ -S fuzzer2 -- ./program afl-fuzz -i testcases/ -o sync_dir/ -S fuzzer3 -- ./program
这两种类型的Fuzzer执行不同的Fuzzing策略,前者进行确定性测试(deterministic),即对输入文件进行一些特殊而非随机的变异;后者进行完全随机的变异
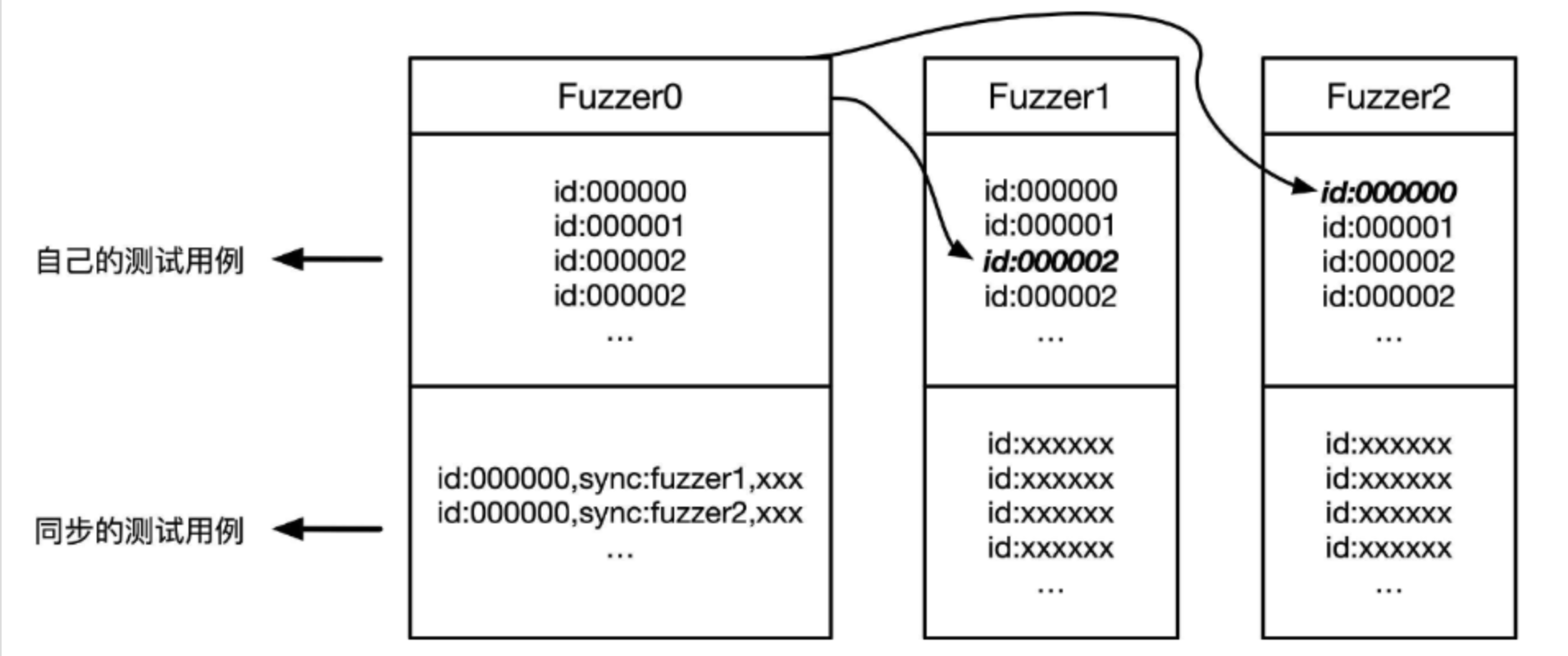
这里可以看到-o指向的是同一个目录,并行测试中所有的Fuzzer相互协作 ,在找到新的代码路径时,相互传递新的测试用例,如下图中以Fuzzer0的角度来看,它查看其它Fuzzer的语料库,并通过比较id来同步感兴趣的测试用例
afl-whatsup可以查看每个fuzzer的运行状态和总体概况,加上-s参数只显示概况,其中的数据 都是所有fuzzer的总和
afl-gotcpu可以查看每个核心的使用状态